Editor
At a High Level:
- Compose: the glue
- ComposeEditor: currently Ace based | pluggable dialects (dbsql, python…)
- ComposeAutocomplete: Ace native | Hue | Remote
Architecture
Overall editor architecture
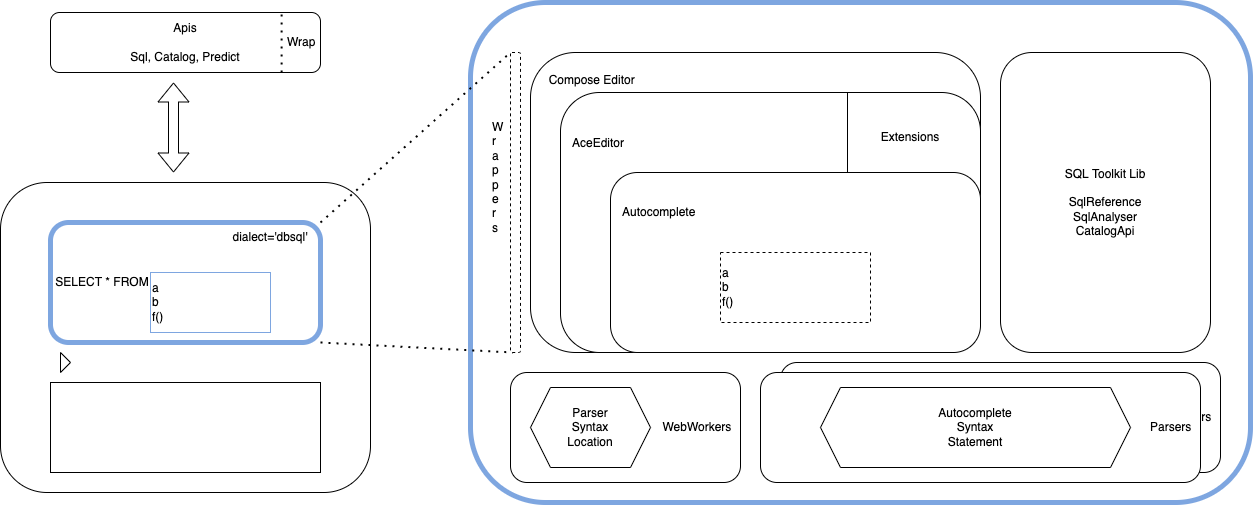
Live syntax behaviors architecture
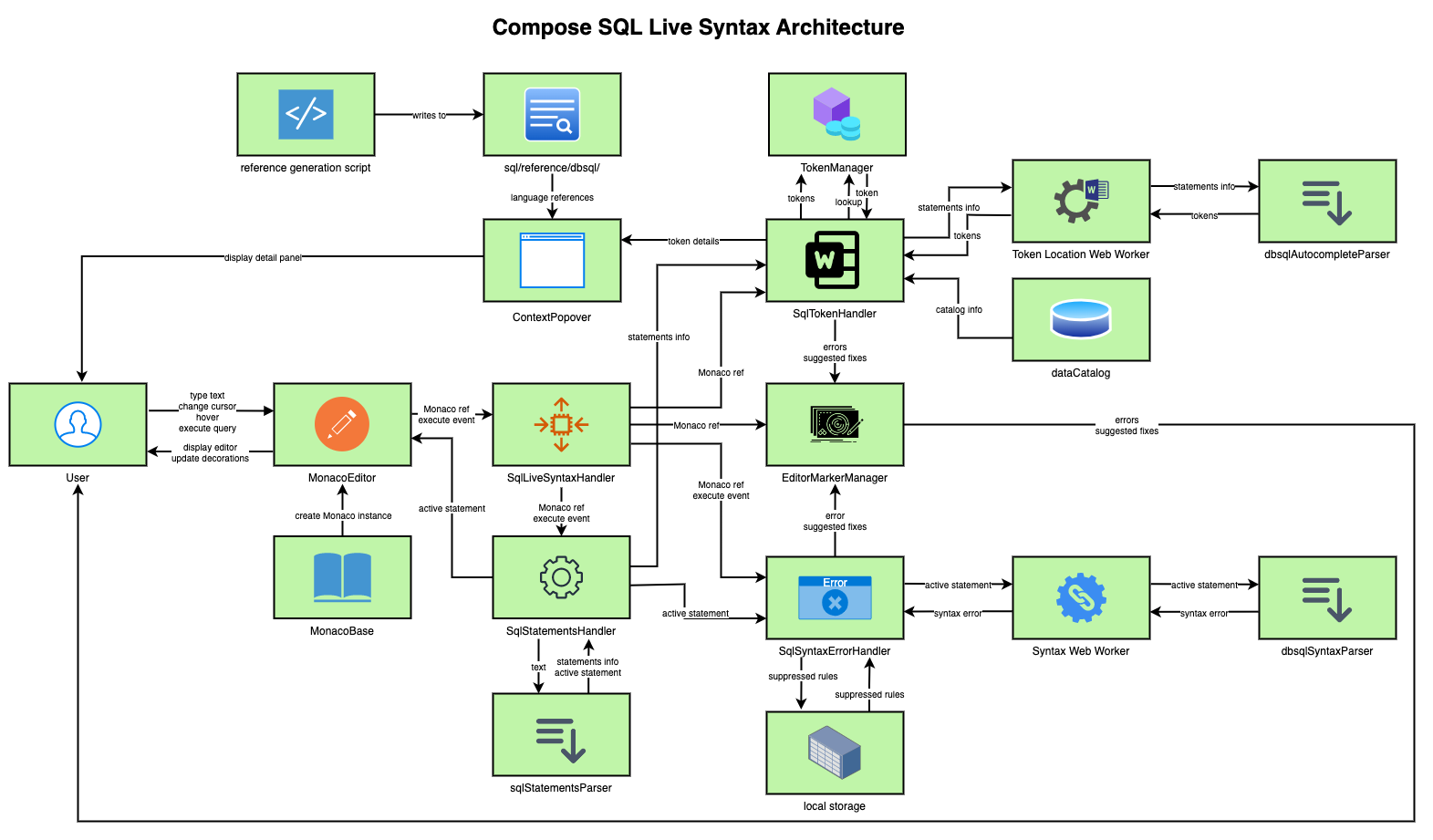
Pre-execution Error Highlighting & Token Lookup
Whenever the user moves the cursor or the query text changes, the editor will find the active statement and parse it for syntax errors and token locations. (Parse happens on cursor move because not only does the active statement change, the parse result also depends on the cursor location.) It will then underline syntax errors and token-not-found errors and allow the user to right-click on schema objects, functions, asterisks, etc to view more details.

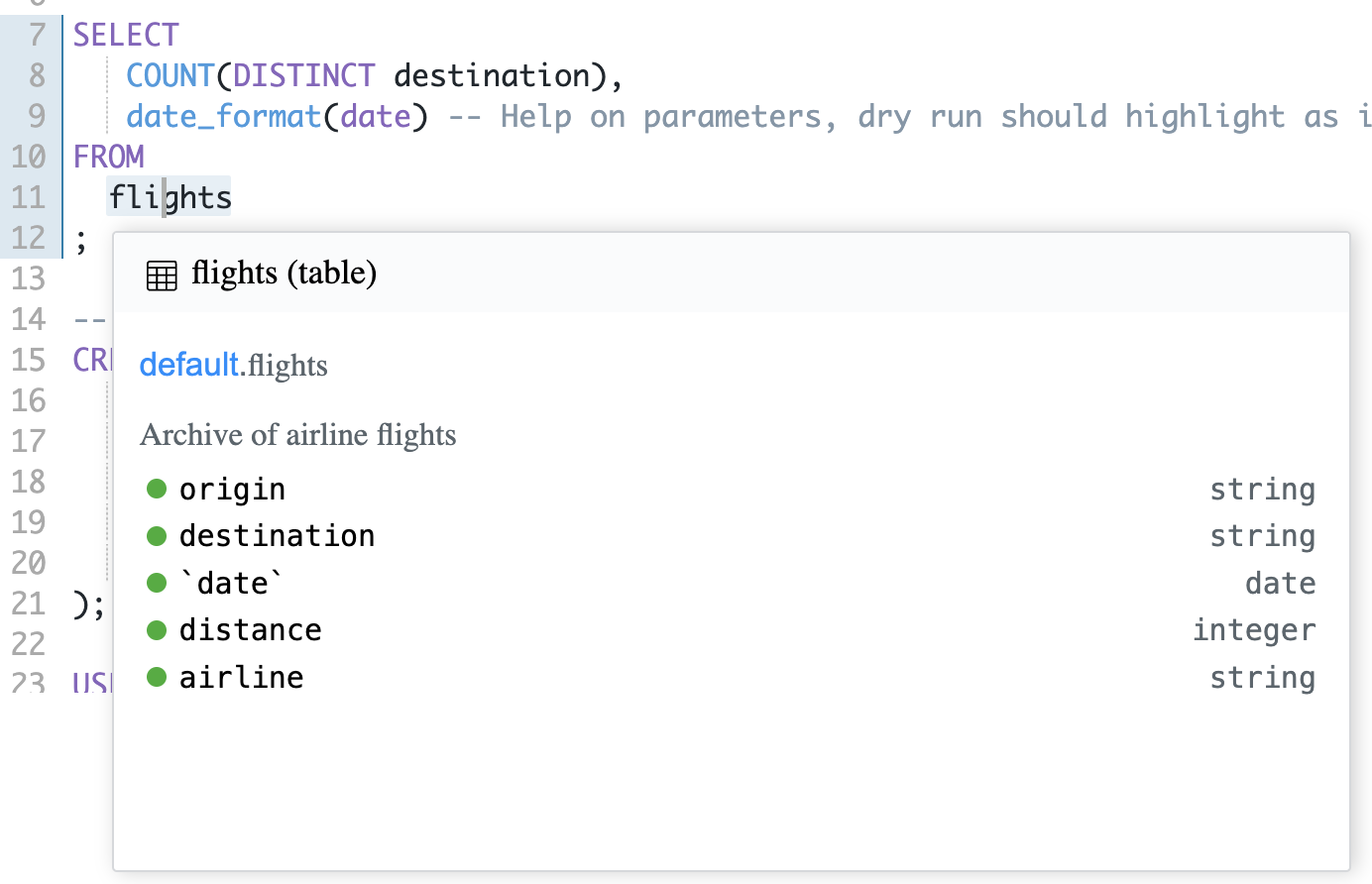
The logic for anything related to statements parsing, token parsing, token lookup, and syntax error checking is located in AceLocationHandler.ts for Ace and SqlLiveSyntaxHandler (and its internal classes) for Monaco. This class interfaces with the two web workers that in turn use the three parsers to parse the statements, tokens, and syntax errors.
The logic is tested in AceLocationHandler.test.ts and monacoEditor/*.test.ts.
Gutter statement decorations
The active statement has the corresponding line numbers in the gutter highlighted blue.
Post-execution Error Highlighting
After a query finishes executing, the execution error and warning messages can be passed in via the messages prop, and will be highlighted in the editor.

Syntax highlighting
The editor provides color highlighting for keywords, string/numeric literals, functions, backticked identifiers, comments, etc. In Ace, the highlighting of keywords and functions is purely based on the token value, not its surrounding context. This means an unbackticked column date would be highlighted as a keyword.
New keywords might not be properly colored highlighted in the editor. This is especially true when adding a new language. Here is how to fix that.
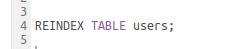
Missing highlighting for ‘REINDEX’ keyword
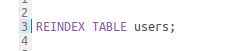
With correct highlighting
Updating keywords
The Editor is currently visually powered by Ace. The list of supported languages is found in the mode directory.
For each dialect, we have two files. e.g. with PostgreSQL:
pgsql.js
pgsql_highlight_rules.js
The list of keywords is present in *_highlight_rules.js and can be updated there.
var keywords = (
"ALL|ALTER|REINDEX|..."
)
After modifying files under tools/ace-editor run the following to refresh ext/ace with the new modes:
cd tools/ace-editor
yarn
./regen-ace.sh
Adding new dialect
To add a new dialect, it is recommended to copy the two files of the closest mode and rename all the names inside. For example, if we were creating a new ksql mode, pgsql_highlight_rules.js would become ksql_highlight_rules.js and we would rename all the references inside to psql to ksql. Same with pgsql.js to ksql.js. In particular, the name of the mode to be referenced later is in:
KsqlHighlightRules.metaData = {
fileTypes: ["ksql"],
name: "ksql",
scopeName: "source.ksql"
};
Tip: inheritance of modes is supported by Ace, which make it handy for avoiding potential duplications.
Language references
The tools for generating the embedded language reference manuals can be found under tools/references.
DBSQL
You can update all built-in functions with yarn build:reference or by running
tools/references/dbsql/generate_functions_from_docs.py.
This Python 3 script searches for built-in Spark SQL functions from the Databricks docs repo: https://github.com/databricks/docs. The list of functions are parsed from https://github.com/databricks/docs/blob/master/source/sql/language-manual/sql-ref-functions-builtin.md and more details are obtained from the individual function pages like source/sql/language-manual/functions/approx_percentile.md. The online page can be found at https://docs.databricks.com/sql/language-manual/sql-ref-functions-builtin.html.
With this information the script generates:
- The file
js/sql/reference/dbsql/builtInFunctionReference.ts, which is used by autocomplete as the source of truth for what built-in functions can be suggested - The aggregate functions portion of the files
js/parse/jison/sql/dbsql/sql.jisonlexandjs/parse/jison/sql/dbsql/udf/aggregate/aggregate_common.jison, which are used by the jison parsers - The functions portion of the file
tools/ace-editor/lib/ace/mode/dbsql-highlight-rules.js, which is used to determine syntax highlighting. This file is then used to generatejs/ext/ace2/mode-dbsql.js
Clone the databricks/docs repo to the same directory that universe (or hue2redash) is in before running
this script. The script will pull from the latest master in docs as well as run Prettier on the output files.
Updating the function documentation reference works in both universe and hue2redash, but updating syntax
highlighting only works in hue2redash. To update highlighting in universe, you must first run the script in
hue2redash, then run yarn build:ace, and finally copy the generated results in js/ext/ace2/mode-dbsql.js
over to universe.
The script will also include timestamps in the output files indicating when they were generated.
Command line arguments:
--testor-t: Run unit tests. You can also useyarn test:scripts.--no-write: Specify not to write to certain output files. Options areall,reference,jison, andhighlighting. You can specify more than one of these.--no-print: No printout except errors.--no-pull: Don’t pull from latest master in the docs repo.
Types are parsed from the doc string but can be missing or even wrong (missing types default to
SqlType.T). For now, doesn’t support multiple possible function signatures (only the last seen
signature is used). Assumes all functions can be used as analytic functions. Doesn’t support
flexible number of arguments (the “…").
Since this script uses the docs as its source of truth (sans some formatting such as adding spaces after commas). This means that it inherits any errors or typos in the docs. If you find any errors, report them to the docs team, as fixing them here would not be a permanent solution.
The script prints out some information that may be useful. Note that the doc’s function list page has some duplicate functions in different sections, and that is not an error.
The output for js/sql/reference/dbsql/builtInFunctionReference.ts is the list of built-in functions in the form:
{
functionName: {
name: string,
signature: string,
description: string,
arguments: [
{
name: string,
doc: string,
type: SqlType,
}
...
],
returnDoc: string,
returnTypes: SqlType[],
draggable: string,
isAggregate: boolean,
isAnalytic: boolean,
},
...
}
Hive
The Hive documentation is generated directly from the Hive wiki by using an exported epub file.
-
Goto https://cwiki.apache.org/confluence/display/Hive/LanguageManual
-
Click the three dots ‘…’ in the upper right corner
-
Click ‘Export to EPUB’
-
In the Hue folder run:
node tools/references/hive/hiveExtractor.js --epub /path/to/epub/file
Impala
The Impala documentation is generated from the ditamap files in the Impala GitHub repo.
-
Clone the Impala repo next to hue from https://github.com/apache/impala
-
In the Hue folder run:
node tools/references/hive/docExtractor.js -c hue -f ../impala/docs/ -d impala_langref.ditamap,impala_keydefs.ditamap,impala.ditamap -o desktop/core/src/desktop/static/desktop/docs/impala/ -m desktop/core/src/desktop/templates/impala_doc_index.mako
Monaco Editor
A subset of features of the Monaco editor are used when monaco-editor-enabled is on. The features are imported in js/ext-monaco/MonacoBase.ts. This is not to be confused with the similar library vscode-languageserver-protocol which is used for the LSP.
The dialect reference files are located in js/ext-monaco/languages/.
Ace Editor
When monaco-editor-enabled if off, a modded version of the Ace Editor is used. The source is located in tools/ace-editor/. If you change anything in that folder, you need to re-compile it into js/ext/ace2/:
cd tools/ace-editor
yarn # only once
./regen-ace.sh
Do NOT edit anything in js/ext/ace2/ directly as it will be lost once the script is re-run.
Editor themes:
js/apps/editor/components/aceEditor/AceEditor.scss
js/ext/ace2/theme-hue.js
Dialect:
tools/ace-editor/lib/ace/mode/dbsql_highlight_rules.js
Highlighter classes
hue-ace-location
hue-ace-syntax-warning
Insertion points:
- Include insertion points in the paste value of query snippets with the format
${number}or${number:placeholder}. For example, a query snippet can beSELECT ${2:*} FROM ${1}. - Insertion points are replaced with their placeholders, and when you press tab, the cursor jumps to the next insertion point in the stack. Tab still selects a suggestion when the suggestion box is open, and it indents when the insertion point stack is empty.
- The order of insertion points is from 1, 2, 3, … and 0 last. If there are ties the rightmost insertion point is first. (This is kind of an odd tie breaker but you aren’t really supposed to have ties anyway.)
- The cursor first jumps to the first insertion point when the snippet is selected. If the last insertion point isn’t at the end, the cursor jumps to the end after the last insertion point.
Web Workers
There are currently two web workers that run parallel to the editor main thread. The main thread will send them messages, they perform parsing on the text given, and return the results.
- Token location web worker
- This web worker runs the autocomplete parser on the statement, but ignores the autocomplete information and only saves the
locationsattribute of the parse result. It then does some additional processing and returns information on what tokens were present in the query, including token identifier chain, location, and type. - It can find tokens in multiple statements at a time.
- This web worker runs the autocomplete parser on the statement, but ignores the autocomplete information and only saves the
- Syntax web worker
- This web worker runs the syntax parser on one statement and decides if it is valid. If not, it finds the syntax error, including which token errored and what suggested fixes are.
- The syntax parser can only find one syntax error at a time since it stops as soon as it encounters one.
- Token-not-found errors are found with a completely separate mechanism.
- Autocomplete web worker
- There was an attempt to add a web worker that computes autocomplete parsing and suggestion generation, but it was not finished due to the difficulty in sharing the catalog information.
- There is also a web worker for the LSP’s autocomplete that is unrelated.
Note that autocompete parsing and statement parsing are not done in web workers. Autocomplete parsing is not performed continuously, only when the user types, and statement parsing is extremely fast.